Rechercher du texte dans un jeu
Rechercher du texte dans un jeu
Ce tutoriel va vous apprendre comment faire une recherche relative sur un JV dans le but d'y trouver du texte non compressé .
Heureusement pour nous , tous les jeux n'ont pas du texte compressé , si tel est la cas ça compliquera sans nulle doute la tâche , mais pour un débutant il est mieux de commencer pas à pas et donc de trouver un jeu dans lequel il vous sera facile de trouver les scripts .
1. L'encodage ASCII
Avant de commencer , il vous faut savoir une petite chose qui peut avoir son importance , dans votre éditeur hexadécimal , les caractères qui sont dans la partie "texte" (à droite de ce dernier) sont encodés en ASCII . Cela signifie que chaque caractère de l'alphabet ou de la ponctuation sont sur 1 octet et possèdent chacun leur propre valeur .
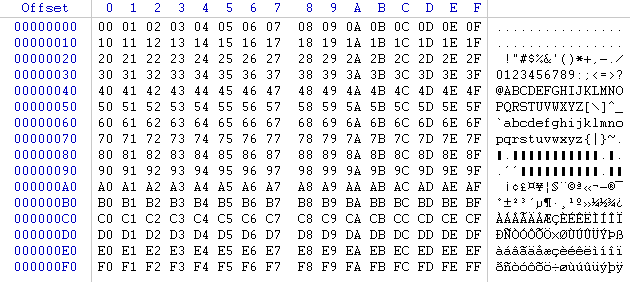
Pour exemple dans le screen ci-dessus , j'ai noté les caractères allant de 0x00 à 0xFF , vous verrez qu'on y trouve tous les caractères de notre alphabet ainsi que notre ponctuation (entre autre) .
2. Quelques infos sur les textes dans les JV
Même si dans certains JV les textes sont visibles à l'oeil nu via un éditeur hexadécimal , ce n'est pourtant pas toujours le cas .
En effet les JV ne sont pas tenus de respecter la norme ASCII , vos caractères alphabétiques ou ponctuations peuvent donc posséder d'autres valeurs , ce qui fait qu'on ne pourra pas toujours voir les textes d'un jeu aussi facilement et qu'il nous faudra donc avoir recours à une recherche relative dans le but de les trouver .

Exemple de textes visibles à l'oeil nu
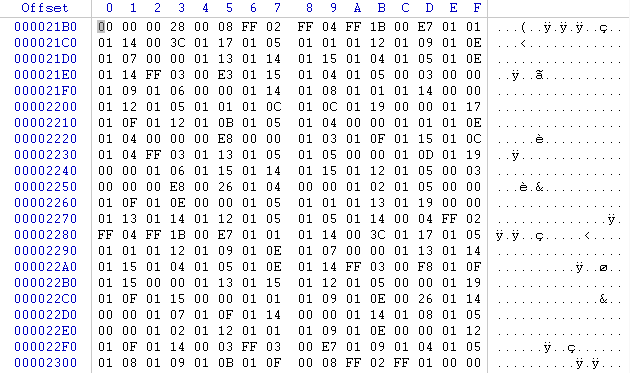
Exemple de textes non visibles à l'oeil nu
Sur le 1er screen ci-dessus , pas de doute possible , les textes se reconnaissent de suite , mais sur le 2nd qui pourrait penser qu'il s'agit bien là des textes d'un JV , et c'est pourtant bel et bien le cas
Une autre chose importante à savoir , les caractères dans un JV ne sont pas non plus systématiquement sur 1 octet par caractère , ils peuvent tout aussi bien être sur 2 octets par caractère (pour exemple , ce n'est pas rare sur les jeux Jap ou sur les jeux NDS) .
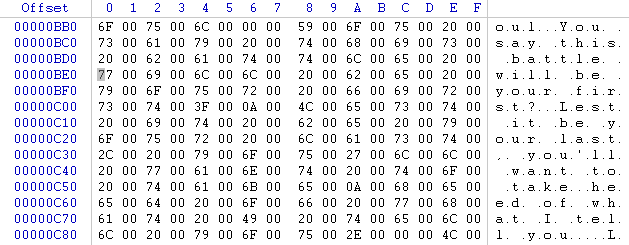
Exemple de textes sur 2 octets par caractère visibles à l'oeil nu
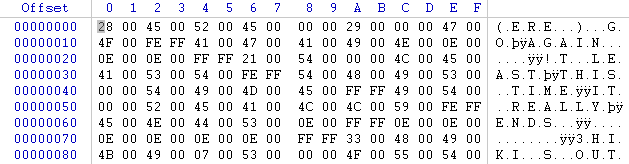
Exemple de textes sur 2 octets par caractère partiellement visibles à l'oeil nu
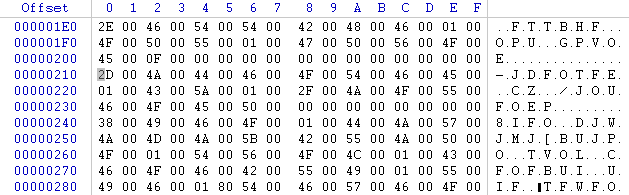
Exemple de textes sur 2 octets par caractère non visibles à l'oeil nu
Comme vous pouvez le constater sur les screens ci-dessus , chaque caractère est sur 2 octets (ex/ a=6100 sur le 1er screen) , il faudra bien penser à prendre cela en compte lorsque vous ferez une recherche relative de vos textes .
3. La recherche relative
Avant de rentrer dans le vif du sujet , il vous faudra déjà comprendre comment fonctionne une recherche relative , sur quelle logique celle-ci est basée .
Comme nous l'avons vu dans la 1ère partie , l'encodage ASCII attribue à chaque caractère un octet d'une certaine valeur toujours fixe (Ex/: A=41 , B=42 , C=43, ... , a=61 , b=62 , c=63 , ...) . On constate donc que pour les lettres de l'alphabet , la valeur s'incrémente de 1 en suivant l'ordre alphabétique aussi bien pour les majuscules , que pour les minuscules .
La recherche relative va donc suivre la même logique , elle va checker les octets du fichier sur lequel vous l'utiliserez , dans le but de trouver un mot clef (présent dans le jeu) que vous lui indiquerez vous même , en tablant sur le principe que "si A=(valeur x) , B= (valeur x+1) , C=(valeur x+2) , D=(valeur x+3) , etc ...
Quoi de plus adapté pour trouver du texte non visible finalement puisqu'en théorie , l'ordre alphabétique sera quasi systématiquement respecté même si vos textes ne sont pas en ASCII
Dans la pratique , ce système est relativement simple et efficace à partir du moment ou les textes sont en 1 octet par caractère , mais dans le cas ou ils sont en 2 octets par caractère , ça complique quelque peu la tâche . Il existe heureusement des logiciels de recherche relative qui permettent d'utiliser un caractère "joker" ce qui permettra donc au logiciel de checker seulement un caractère sur 2 et cela se révèlera très pratique pour vos recherches .
On trouve plusieurs logiciels de recherche relative comme Search RX , Search R3 , etc ... que disponibles sur le site de la TRAF , mais dans ce tutoriel je vais vous proposer "Monkey-Moore" codé par Darkl0rd , puisque ce dernier gère les caractères "joker"dont je vous parlais précédemment , ainsi que les caractères Jap .
Lien pour Monkey-Moore : monkey-moore-v0.4
Voyons un peu son interface :
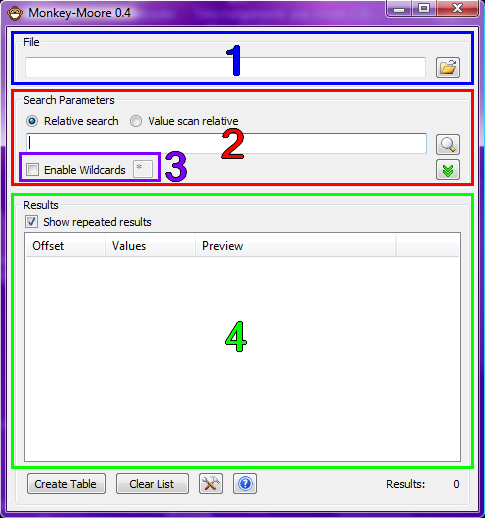
- Il s'agit juste de l'emplacement ou vous mettrez le fichier dans lequel vous souhaitez rechercher du texte
- C'est ici que vous rentrerez le (ou les) mot(s) clef que vous aurez préalablement repéré dans le scénario du jeu , tant qu'à faire essayez de choisir un mot pertinent , et de préférence entièrement en minuscules dans un 1er temps
- Case à cocher qui vous permettra d'utiliser si activée un caractère "joker" dans vos mots clef
- Cette fenêtre est dédiée au résultat de la recherche
En pratique ça donne :
- Pour commencer je lance le jeu dans le but de dénicher quelques mots clefs que j'utiliserais dans ma recherche relative pour trouver du texte

- Dans mon jeu , ce texte apparait lors de l'introduction (l'opening) .
Par chance dans l'arborescence des fichiers du jeu je trouve comme par hasard un fichier qui se nomme "OpeningText.mbb" , coup de bol car ce nom semble tout à fait pertinent , je regarde donc ce qu'il contient avec mon éditeur hexadécimal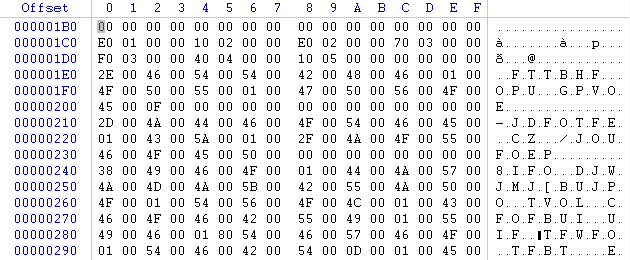
Au vu de la forme du code dans le fichier , j'en déduis qu'il s'agit bel et bien de textes en 2 octets par caractère (0x00 entre chaque caractère) mais pas encodés en ASCII car impossible de lire quoi que ce soit - Je tente donc une recherche relative dans ce fichier en utilisant le mot clef "civilization" car il est long , en minuscules et il correspond donc tout à fait à la situation . Comme j'ai remarqué qu'il y a de fortes chances pour que mes caractères soient sur 2 octets , j'active l'option "joker" et je tape mon mot en prenant bien soin d'insérer le caractère joker entre chaque lettre (c*i*v*i*l*i*z*a*t*i*o*n) puis je lance ma recherche .
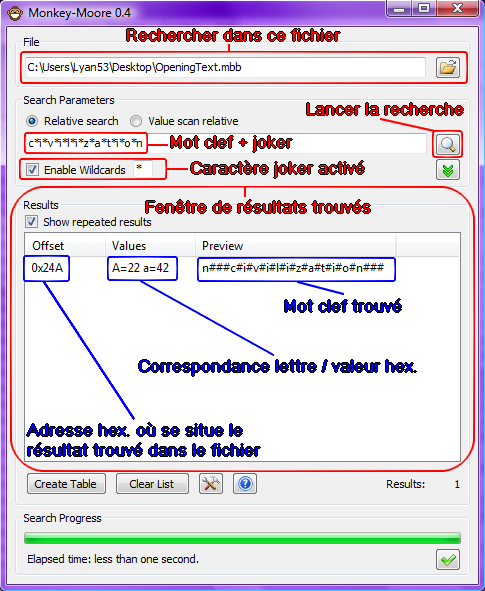
Comme vu sur le screenshot , Monkey-Moore trouve donc 1 résultat de recherche , il vous indique l'adresse où se situe celui-ci dans le fichier , ainsi que la valeur hexadécimale des lettres "a" et "A" qu'il a trouvé pour que votre mot clef corresponde .
Attention néanmoins , comme vous n'avez pas utilisé de mot avec des majuscules , seule la valeur attribuée au "a" minuscule est à prendre en considération .
A partir de ce résultat obtenu vous pouvez donc facilement déduire que : si a=42 , alors b=43 , c=44 , d=45 etc ... Vous allez donc pouvoir commencer à mettre en place une "table de caractères"
4. La table de caractères
Une fois que vous avez réussi à identifier les valeurs attribuées à certains caractères dans vos fichiers contenant du texte , il est temps de commencer à mettre en place une table de caractères . Notez que la mise en place d'une table de caractères est à faire quel que soit l'encodage (même si c'est du ASCII) .
Celle-ci vous sera utile principalement pour 2 raisons :
- La première est simplement que certains éditeurs hexa vous permettront d'utiliser une table de caractères sur votre fichier (WindHex32 , Translhextion) , vous aurez donc la possibilité de pouvoir lire directement votre texte non ASCII dans celui-ci
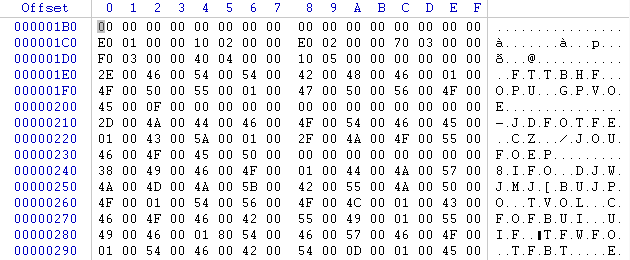
Sans table de caractères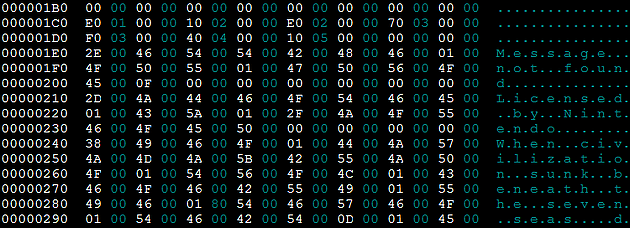
Avec table de caractères - Le seconde pour la simple raison que c'est grâce à une table de caractères que vous pourrez extraire et réinsérer les scripts dans un fichier .txt par exemple .
Il vous faudra partir du principe qu'il sera nettement plus pratique à un traducteur de travailler sur un fichier .txt , que directement avec un éditeur hexadécimal , c'est pour ainsi dire un très gros gain de temps mais également un confort non négligeable pour diverses raisons sur lesquelles nous ne nous étendrons pas dans ce tutoriel .
Revenons donc à nos moutons : comment construire une table de caractères et avec quel outil ?
Un simple bloc-note windows (ou notepad) suffira pour ce faire . Il vous suffit d'ouvrir un fichier .txt tout bête dans lequel vous noterez vos correspondances en suivant ce principe : valeur hexa=caractère
Un seul valeur=caractère par ligne et aucun espace superflu car il sera compté comme caractère à part entière sinon
Exemple avec un extrait d'une table ASCII :
- Code: Tout sélectionner
20=
41=A
42=B
43=C
44=D
61=a
62=b
63=c
64=d
Une fois tous vos caractères entrés , enregistrez simplement votre fichier et remplacez l'extension ".txt" par ".tbl" , c'est tout , ce n'est pas plus compliqué que ça
Dans le cas ou votre table de caractères contient 2 octets par caractère , il vous suffira alors de procéder ainsi :
- Code: Tout sélectionner
0100=
2200=A
2300=B
2400=C
2500=D
4200=a
4300=b
4400=c
4500=d
Pour reprendre l'exemple donné plus haut dans lequel j'ai utilisé une table sur 1 octet , voilà ce que ça donnera avec un table plus adaptée au texte en question (donc sur 2 octets par caractère) :
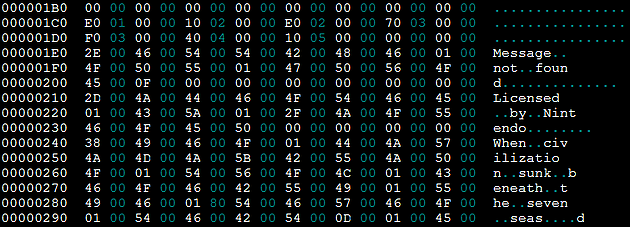
Avec table sur 2 caractères
Dernier point relativement important , certains jeux possèdent plusieurs tables de caractères différentes pour les divers textes que vous y trouverez , c'est à voir selon le cas , mais pensez-y au besoin si vous constatez que votre table ne fonctionne pas
A vous de bien travailler maintenant ...